这几天写了两个东西
- 公众号文章转换及处理
- 定时领券
需求
一直关注品城记,发现它推荐的店铺信息每期都会整理在公众号文章下,大部分格式是正确的(预想的太美好,其实最后也就30%的转换率。人工维护的信息都有偏差)

直接用charles抓包,然后使用php进行批量处理。
思路:文件处理、正则匹配、字符处理、简易ORM、小程序云开发
最近京东年货节,一直放大量的券,京东领券对消费者还是比较友好的。不像猫超,只能靠抢,说你火爆你就没办法。
思路:CURL、url参数处理、执行脚本、并行 (这玩意的效果感觉跟js差不多,太菜了我)
公众号文章转换
Step 1
抓包抓到的Responding直接保存为文件(只抓了列表页,其中携带文章URL和标题),扫描文件获取文本内容
glob($pattern,$flags=0)- 模式匹配文件名 例:
*.jpg / *.txt - 特殊的设定 使用
GLOB_BRACE{a,b,c}来匹配'a','b','c' - 成功返回绝对路径,否则
false
- 模式匹配文件名 例:
scandir ($dir,$sort_order,$context)- 完整路径
- 排序方式
- 返回相对路径
readdir(resource $dir_handle)opendir()打开的资源参数
Step 2
提取目标格式中的信息。文本数据不完全规范,需要多次处理。一开始想使用正则,但是对于相交的区间,正则并不能处理,后改用explode。使用explode后就需要对数组进行多次处理了,相对麻烦。
str_replace(mixed $search,mixed $replace,mixed $subject,int $count = 0)search与needle同义- 如果
replace的值的个数少于search的个数,多余的替换将使用空字符串来进行。 - 如果
search是一个数组而replace是一个字符串,那么search中每个元素的替换将始终使用这个字符串。 count如果被指定,它的值将被设置为替换发生的次数- 替换多维数组中的字符串时可用json_encode而不是遍历,效率更高。 参考php手册中高赞笔记
strstr($haystack,$needle,$before)如果你仅仅想确定
needle是否存在于haystack中,请使用速度更快、耗费内存更少的 strpos() 函数。- 返回
needle之后/之前的字符串
- 返回
substr()/mb_substr($str,$start,$length,$encoding)这个太熟悉了。说下mb_substr吧,是按字符的字节长度来截取。
意思就是utf-8编码下占三个字节的汉字算一个截取长度
strip_tags($str,$allowable_tags)由于 strip_tags() 无法实际验证 HTML,不完整或者破损标签将导致更多的数据被删除。
输入 HTML 标签名字如果大于 1023 字节(bytes)将会被认为是无效的,无论
allowable_tags参数是怎样的。- 从字符串中去除 HTML 和 PHP 标记
- 使用可选的第二个参数指定不被去除的字符列表。
- htmlspecialchars() - 将特殊字符转换为 HTML 实体
addslashes($str)- 使用反斜线引用字符串
- 可用于数据库插入时去掉引号,避免插入失败
preg_replace_callback($pattern,$callback,$subject)- 执行一个正则表达式搜索并且使用一个回调进行替换
1
2
3
4
5
6
7
8
9
10public static function filter_Emoji($str)
{
$str = preg_replace_callback( //执行一个正则表达式搜索并且使用一个回调进行替换
'/./u',
function (array $match) {
return strlen($match[0]) >= 4 ? '' : $match[0];
},
$str);
return $str;
}
preg_match_all($pattern,$subject,$matches,$flag,$offset)flag有几个不同的标记值,用于不同的输出offset是偏移量,从目标串偏移位置开始匹配,1开始计数好奇这个函数为什么不能匹配相交的区间,看了以下的C源码。
分了三个部分:
1)regex 2)match 3)error
用到了挺多的
goto(以前写C++打题的时候从来不用switch、goto以及do while,很有意思。)如何查找源码呢,
php-src仓库Cmd+shift+F->_function(func_name)
此处使用了jit(即时编译)后,速度比不使用快10倍之多,JIT可以决定是否将代码编译,从而提升执行速度
除了一堆宏定义与异常处理之外,
pcre就是个库。本质上还是C的strcmp()与for循环。发现新世界的大门…….
Step 3
PDO写入数据库,需要正确输出,捕获异常等,这个函数涉及较少,实现调用时思路都大同小异吧。
- 单例模式复用数据库连接
insert($field)拆分数组键值对,拼装sql,绑定参数(需要判断参数类型)exec()需要数据输出则使用fetch不需要则返回bool值- 异常捕获
定时领券
Step 1
使用charles 抓取京东的请求,提取url和请求参数,必须拿到cookie。使用代码封装请求,并测试。
- CURL系列函数 (不多说,用到直接查就好,其实用composer的扩展包更友好)
urlencode()看参数中是否会携带引号等字符,使用这个函数转换
Step 2
使用代理ip、多线程跑。
测试的代理ip被拦截的严重,最后也没用上。
- 检测代理ip有效性 以下代码引用,from 搜索引擎结果,仅提供思路
1 | /** |
使用
curl_multi_*()相关函数 并行地处理批处理cURL句柄效果如下图:
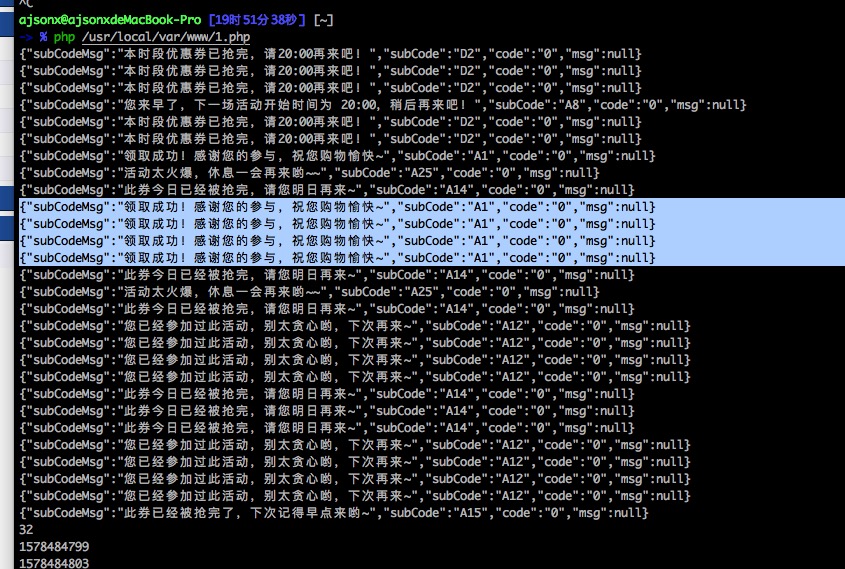
参考文章
在文中已全部引用