祝大家拿到好offer
- 近期面试心得
- 一年的PHPer面试复习手册
- 深圳PHP岗位面经
- 有些问题抛出来了,没有回答。
- 还有一部分基础知识需要靠积累,没有整理出来。
- 面试还会继续,本篇文章今年内不定时更新。
自我介绍 别紧张 讲慢点 开录音 警惕面试官挖坑 大胆讲
自由发挥的问题
项目中遇到的困难
职业规划
接受一个新事物能力如何
系统设计题
评论回复点赞如何设计
设计表,针对业务场景进行分析:
- 需要查询出帖子下的所有评论
- 需要查询出评论下的所有回复
- 需要查询出回复的回复
- 评论是否点赞标识,以及点赞数
考虑到以上,思考设计出表结构即可。
大数据量场景
- 点赞取消频繁(Redis缓存)
- 频繁查询评论(ES)
- 数据量过大(分表策略)
高并发系统考点
如何应对突增的流量?(可预测流量与不可预测流量)
缓存
- Redis 5种基本数据结构及常见使用场景
- String
- K-V 缓存
- Hash
- 存储对象,部分数据变更
- List-双向链表
- 消息队列
- 利用zipList来代替大量的K-V
- 粉丝列表(非严格实时场景)
- Set-HashTable
- 无序不重复集合
- 共同关注
- Zset-HashMap&SkipList
- 有序不重复集合,并且带一个权重参数
- 排行榜
- String
- Redis加锁,原子操作 EX | NX
缓存故障
缓存穿透:大量查询持久层中为空的值。
- 把为空的值也放入缓存
缓存雪崩:某一个时间段,缓存集中过期失效
- 设置随机过期时间
缓存击穿:热点Key失效的瞬间,直接并发访问持久层
- Key永不过期
降级
- 功能暂时下线
限流
三种常见的限流算法:
- 计数器算法:单个接口1分钟访问次数不能超过100。此算法可能在59秒到1分01秒内被访问200次
- 滑动窗口算法:将时间分为多个格子,每个格子有独立的计数器
- 令牌桶算法:所有请求在处理之前都需要拿到一个可用的令牌,根据限流大小,按一定速率往桶里添加令牌,桶设置最大的放置令牌限制,业务逻辑处理完后将令牌删除
- 漏桶算法:水以任意速率流入,一定速率出水,超过桶容量就丢弃。
既然有 HTTP 请求,为什么还要用 RPC 调用?
- 通用定义的http1.1协议的tcp报文包含太多废信息
- 牺牲可读性提升效率、易用性是可取的
算法
O(logN)究竟是多少?
为什么没有底数?
由于log级别的时间复杂度都是使用了分治思想,这个底数直接由分治的复杂度决定,如果是二分法,底数就是2。无论底数是什么,log级别的渐进意义是一样的。高数中极限的思想。
递归和回溯的区别
递归可以理解为是函数自己调用自己,有一个终点。而回溯就是我们经常说DFS(深搜)的一种,特点是有回头路。
单调栈
问题描述:蓄水问题,高度为 i 的方块能蓄多少水。例:[1,3,2,4,3,5]
将水池抽象为数组,维护一个单调递减的栈。对当前元素进行遍历,如果当前元素大于栈顶元素,则进行弹出(pop)操作,利用此时的栈顶元素进行蓄水容量计算(为什么可以?因为我们维护的是单调递减的栈,所以栈顶的元素减去弹出的元素一定大于等于0)。栈空或栈顶元素大于当前元素,进行一次入栈。
这个问题不用单调栈去解决更容易理解,这里还有两种值得学习的思想
常规的一种思路是O(N^2),遍历找出当前位置左边最高的(O(N))和右边最高的(O(N))。
这种方法很好优化,我们可以利用备忘录记录一下。即用两个数组
Left和Right数组预先处理一下,记录 在下标为 i 时,左边最高的和右边最高的方块高度。此时时间复杂度为O(N),空间复杂度为O(N)
还有一种做法比较不容易想到。对于这个数组,它的最大值假设为
arr[i],它的左边(0…i-1)是非严格单调递增的,它的右边是非严格单调递减的。我们可以找出这个最大值,分别遍历0…i-1 和 n…i+1。实时更新相对另一侧的最大值(中间的最大值我们已经固定了,我们只要固定旁边两侧的最大值。)并计算出积水量就好了。还有一种双指针做法与之类似。
来LeetCode试试吧 Leetcode #接雨水
Hash 链地址法
- 问题描述:当两个不同的关键字求得的索引相同时,如何存储。是处理hash冲突的其中一种方法。
- 将冲突的值,以链表的形式连起来。
- 应用:PHP 数组底层实现
二叉查找树
- 左子树不为空,左子树的值均小于根节点的值
- 右子树不为空,右子树的值均大于根节点的值
- 任意节点的左右子树均是二叉查找树
- 没有值相等的节点
中序遍历输出从小到大的顺序排序
缺点:退化为有n个节点的线性链
平衡二叉查找树
- 平衡条件:左右子树高度差不超过1
- 解决了二叉查找树的退化问题
B树
- 非叶子结点最多只有M个儿子,M>2
- 根节点的儿子数 [2,M]
- 除根节点外的非叶子节点的儿子数 [M/2,M]
- 每个节点存放至少 [M/2-1]
- 对于每个非叶子结点上的指针。P[1] 指向小于K[1]的子树,P[M]指向大于K[M]的子树。在两区间的P[i]指向属于 (K[i-1],K[i])的子树
- 所有叶子节点位于同一层
- 关键字(值)=指针数-1
图片转自CSDN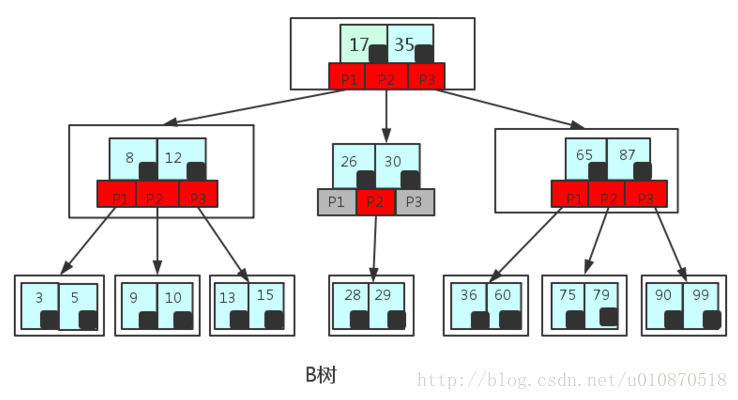
B+树
- 非叶子节点的子树指针和关键字个数相同
- 为所有叶子节点增加了一个链指针
- 所有关键字都在叶子节点出现,用链表存,且是有序的
- 非叶子节点只是叶子节点的索引,叶子节点是存储数据(关键字)的数据层
- 更适合文件系统
- 特点:查询效率更稳定,读写磁盘代价更低
图片转自CSDN
B树在提高了IO性能的同时并没有解决元素遍历效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
最短路
Dijkstra
- 贪心,不能处理负边
- 维护一个
d[i],表示起点到i的最短距离。初始化一个二维数组,表示有向图的路径长度,如果不存在通路则为无穷大。从起点开始选择一个最近的点i,然后将i作为中间点,更新到达的点d[n]值,不断贪心寻找。
Floyed
- 多源最短路、能处理负边,但是不能出现负环。DP思想,时间复杂度:O(n3)
- 枚举中间点,枚举起点,枚举终点。dp表记录最短路。
- 状态转移方程:
d[i][j][k] = min( d[i][k][k-1] + d[k][j][k-1] ,d[i][j][k-1] )
最小生成树
Kruskal
- 贪心,不断加边
Prim
- 贪心,不断加点
DP
Todo,不常考,了解DP思想即可(自底向上的解决问题)
MySQL
Mysql优化
- 选择合适的数据库引擎
- 配置优化
- Sql优化
- 索引优化
- 读写分离
- 表结构优化
- 硬件升级
数据库隔离级别
- 读未提交 RU
- 读提交 RC
- 可重复读 RR (MySQL默认级别)
- 序列化 Serializable
分别解决了 脏读,不可重复读,幻读。事务级别越高,性能越差。
什么是事务
事务是一个工作单元、包含了一组数据操作命令,要么都执行,要么都不执行。(结合实际工作去理解用事务的意义)
ACID
- Atomicity原子性:一个事务中所有操作都必须全部完成,要么全部不完成。
- Consistency一致性:在事务开始或结束时,数据库应该在一致状态。
- Isolation隔离性:事务将假定只有它自己在操作数据库,彼此不知晓。
- Durability持久性:一旦事务完成,就不能返回。
MVCC是一种多版本并发控制机制
InnoDB和MyISAM区别
- InnoDB
- 支持事务
- 非主键索引的BTree节点存的是主键,需要根据主键二次查找相应的数据块。
- 一般是行锁,加在索引上。
- 读写之间可以并发,普通级别的select不需要锁(还有更新级别for update)。当查询的记录遇到锁时,用的是一致性的非锁定快照,读被锁定行的快照。其它更新或加锁读用的是当前读,读取原始行
- MyISAM
- 不是事务安全的
- 数据是顺序存储的,存储方式是非聚簇索引
- 所有索引的BTree节点是一个指向数据物理位置的指针,所以不建立主键都行
- 表锁,只有读读之间是并发的,写写是串行的
- 读和写可以并发,需要设置
concurrent_insert参数 - 写优先级高于读,会导致读请求饿死
一条SQL执行的很慢的原因
- 分两种情况:1.突然很慢 2.本来就慢
- redo-log 满了去同步到磁盘而繁忙
- 拿不到锁。
show processlist查看当前状态 - 索引失效
索引失效的原因
- where子句中使用
!=或者<>操作符 - where子句中使用
or来连接条件 - 避免where子句中对字段进行表达式操作 where num/2 =100
- where子句中对字段进行mysql函数操作
- 最左前缀原则
- 列类型是字符串,一定要在条件中使用引号
- like的模糊查询以%开头
###关于联合索引的特别提醒
- 对于联合索引(a,b,c)来说,有效的索引查询分别是(a),(a,b) ,(a,b,c) 联合索引在数据结构下相当于 Order By a b c
- 对于查询语句来说,不管你where语句怎么写的,b写在前面,a在后面也没关系。MySQL会优化你的查询语句,依然会命中索引
- 当表中的字段仅仅只有联合索引,没有其他的字段时,不管你怎么写都会命中索引。因为索引覆盖了。
IN 和 EXISTS的区别
- IN:把外表和内表作hash连接(了解什么是hash join)
- EXISTS:对外表作loop循环,每次loop循环再对内表进行查询
- 如果两表中一个较小,一个较大。则子查询表大的用EXISTS,子查询小的用IN。
- NOT IN 和 NOT EXISTS
- NOT IN:内外表都进行全表扫描
- NOT EXISTS:子查询依然能用到表上的索引
分表的策略
- 垂直和水平
- 取模
- hash(crc32)
- 一致性hash (就是一个环。如果hash环偏斜,所有请求打到同一台机器上,可以增加虚拟节点。)
分布式事务如何保证一致性
- 2PC
- 3PC
- TCC
- MQ,发布订阅
NOSQL
MongoDB和Redis的区别
Redis的connect和pconnect
- 脚本结束之后连接释放
- 脚本结束之后连接不释放,连接保持在php-fpm中
架构
- 网关层
- 业务逻辑层
- 数据访问层
- DB
了解各层的实现方式、实现工具,各层之间的调用方式。了解垂直拆分、水平拆分,了解各种中间件。内容过多,不在此赘述。/不常考
什么是注册中心,常见的注册中心组件
zookeeper(CP)追求数据的强一致性。
consul(AP)追求高可用与最终一致。
CAP
一致性、可用性、分区容错性
服务冗余
多机配置
无状态化
应用服务可以不存储状态有关的值在自己内部。
会话数据放在外部缓存、结构化数据保存在统一的数据库、文件图片通过CDN下发、非结构化数据(文本、评论),可以存在在统一的搜索引擎里面。保存在统一的服务,便于横向拓展
Nginx
设置防盗链
- valid_referers
正向代理和反向代理
- VPN就是正向,使用者可以感知到
- Nginx等服务器就是反向,感受不到
Nginx与PHP通信两种方式
- unix socket
- tcp socket
HTTP/计算机网络
HTTP状态码
想想还是全写出来了,以后也方便查找。不过这东西问的频率也不高。
- 100:客户端应重新发送初始请求
- 101:改用另一个协议
- 200:成功
- 201:创建新资源成功
- 202:请求稍后会被处理
- 203:响应报头可能来自其他服务器
- 204:服务器成功处理、但没有返回任何内容
- 205:处理成功、客户端应该重置数据源
- 206:partial content 处理了部分内容 用于大文件的断点续传
- 300:若被请求的资源在服务器端存在多个表示,而服务器不知道客户端想要的是哪一个
- 301:请求的页面已经永久跳转到新的URL
- 302:临时移动
- 303:查看其他位置
- 304:未修改、 305 只能使用代理访问、307 临时重定向
- 400:错误请求,服务器不理解
- 401:未授权、403 服务器拒绝请求
- 404:未找到、 405 禁用请求中的方法 406 不接受、407 需要代理授权 、408 请求超时…
- 500:服务器内部错误、502 错误网关、 503 服务不可用、504 网关超时、 505 不支持版本
TCP与UDP
TCP通信就像打电话,双方通信之前需要建立连接、双方就位后方可开始会话;而UDP通信就像发短信,一方给另一方发送数据前,并不需要对方就位。
- TCP:可靠性、顺序性、高损耗
- UDP:不可靠、无序、低耗
TCP沾包解决方案
- 报头添加消息类型和数据长度信息
- 报尾添加结束分割符
用户输入 url 到页面显示经历了哪些
- 通过DNS找到对应的IP
- 浏览器缓存
- 本地的Host找对应的IP
- 路由器缓存查找记录
- DNS域名解析
- 通过IP向对应的web服务器发送请求
- 如果是静态文件,Nginx服务器转发
- 如果是php文件,则交由php-fpm处理
OSI 7层模型
已经没人问了
- 物理层:
- 数据链路层:
- 网络层:IP、ICMP、ARP
- 传输层:TCP、UDP
- 会话层:SMTP、DNS
- 表示层:Telnet
- 应用层:HTTP、TFTP、FTP、NFS
PHP
函数
- array_slice
- array_splice
- compact
- chunk_split
- addcslashes
- chr
PHP执行
- 编译为opcode
- Zend引擎处理转换为C指令
- C转换为汇编语言
- 最后变成机器码执行
针对这块问题的深入性探讨,整理自Gong Yong的Blog-值得读:
- 什么是解释性语言?
- 所谓“解释型语言”就是指用这种语言写的程序不会被直接编译为本地机器语言(native machine language),而是会被编译为一种中间形式(代码),很显然这种中间形式不可能直接在CPU上执行(因为CPU只能执行本地机器指令),但是这种中间形式可以在使用本地机器指令(如今大多是使用C语言)编写的软件上执行。这个软件就是所谓的软件虚拟机(software virtual machine)。
- 我们也可以这样去理解PHP是动态语言的其中的特点:运行时才确定数据类型的语言。但按解释型与编译型去区分语言是不准确的。
- 软件虚拟机又是什么?
- 程序虚拟机 被设计用来在与平台无关的环境中执行计算机程序。
- 所以我们可以跨平台(Linux,MacOS,Windows)的使用而不用担心环境问题(类似不同平台字节长度不同的问题)
- 为什么会编译为OPcode?
- 有了上述两点的基础知识,我们可以简单知道PHP的Zend虚拟机引擎就是一种程序虚拟机,将我们编写的PHP代码进行翻译。这里可以分为两大部分:1.编译栈 2.执行栈。我们假设Zend VM的一个OPCode对应虚拟机的一个底层操作。Zend虚拟机有很多OPCode:它们可以做很多事情。随着PHP的发展,也引入了越来越多的OPCode,这都是源于PHP可以做越来越多的事情。你可以在PHP的源代码文件Zend/zend_vm_opcodes.h中看到所有的OPCode。
综上,我们完整地理解了PHP到Zend引擎这块的详细内容。再接下去就是《计算机操作系统》的事情啦。
CGI、Fast-CGI、PHP-FPM
- CGI 公共网关接口,是Nginx与PHP的协议,Fast-CGI是进程管理器
- 传统的cgi协议在连接请求时,会开启一个进程进行处理,而FAST-CGI处理完请求后,不会kill掉这个进程,而是保留复用。
- php-fpm是管理php-cgi的进程管理器。在更改配置后,新的进程加载新的配置,实现平滑过度。
进制转换函数
二进制 bin、八进制oct、十进制dec、十六进制hex
Array数组的底层实现
- Hash Table
- 链地址法
自动加载如何实现
spl_autoload_register:我们new一个不存在的类的时候会触发,进而可以解决类引入(include)
框架路由如何实现
$_SERVER["PHP_SELF"]=>"/index.php"定位入口文件- 通过对
$_SERVER["REQUEST_URI"]=>"/article/get?id=1"获取请求参数,然后?,&切割参数
魔术方法
__get() __set()__call(),__callStatic()- 调用不可访问或不存在的方法时被调用
__toString()__construct(),__destruct()__isset(),__unset()- 对不可访问或不存在的属性调用
isset()或empty()时被调用 - 对不可访问或不存在的属性进行
unset时被调用
- 对不可访问或不存在的属性调用
__sleep(),__wakeup()- 当使用serialize时被调用,当你不需要保存大对象的所有数据时很有用
- 当使用unserialize时被调用,可用于做些对象的初始化操作
__invoke()当以函数方式调用对象时被调用
魔术常量
__FUNCTION____METHOD____CLASS____FILE____DIR____LINE__当前行号__TRAIT____NAMESPACE__
var_dump(1…9) 输出什么
复习的时候看到鸟哥的微博,顺便转载进来了。风雪之隅
输出:10.9
- 被分成三个部分
1.+.+.9 - 最后变成 1 拼接 0.9
- 被分成三个部分
1
2
3
4
5
6
7
8
9
10
//...在PHP5.6之后是个新的操作符叫做Splat operator, 可以用来定义可变参数函数,或者解数组
function foo($a, $b, $c) {
var_dump($a + $b + $c);
}
$parameters = array (1, 2, 3);
foo(...$parameters);
计算机系统
进程、线程、协程
- 进程是系统调度的一个独立单位
- 线程(英语:thread)是CPU调度和分配的基本单位。大部分情况下,它被包含在进程之中,是进程中的实际运作单位。线程可以看做轻量级的进程。
- 每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
- 系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。
- 没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分
PHP为什么是单线程的?
方便自上而下的去编辑/理解代码
虽然pthreads可以实现多线程,但这会造成PHP-FPM的不稳定,线程安全检查也会产生额外的开销,所以PHP的多线程扩展pthreads的作者也只是建议在cli命令行下使 用
多线程可能会引入其他问题:
- 线程读写变量存在着同步问题,需要加锁
- 锁粒度过大会存在性能问题。一个线程运行,其他线程都在等待,无法实现并行
- 可能产生死锁
- 某个线程崩溃,则整个进程崩溃
多进程更稳定
PHP多进程同时读写一个文件
- flock 函数,可设置模式,但性能并不是很好,经常造成死锁
- 读共享锁
- 写独占锁
- 释放锁定
- 锁定堵塞
- 版本号概念的解决方案:拷贝一份,记录修改时间,修改后与对比原文件更新时间。如果不一致则此期间被修改过
进程间通信(IPC)
- 常用管道(短小、频率高,两进程之间通信)、
- Socket 套接字,主要使用TCP
- 共享内存(庞大的数据,多进程通信,配合信号量使用)
- 管道是半双工的,两进程间使用(需要适当的访问权限,如父子),是特殊的文件
- 消息队列不常用
单工、半双工、全双工
- 单工:只能单向传输数据。例:遥控
- 半双工:可以沿两个方向传送,但一个信道同一时刻只能单向传输
- 全双工:两边同时接受、传输数据。例:电话
并行、串行、并发、异步
- 串行:一次只能取得一个任务并执行一个
- 并行:可以通过多进程/多线程的方式执行这些任务
- 并发:并发是一种现象,同时运行多个程序或都个任务,任务可能是并行、也可能是串行执行,是操作系统进程调度和CPU上下文切换的结果
IO多路复用是什么
多路网络连接复用一个io线程。Linux——Epoll
INT占几个字节?
- C++在32位编译器下INT占4字节、LONG占4字节、FLOAT 4字节、DOUBLE 8字节、char 1字节
设计思想、设计模式
MVC是什么
基本没人问
MVC是模型(model)-视图(view)-控制器(controller)的缩写,是一种设计模式。model层负责提供数据,和数据库有关的操作都交给模型层来处理,view层则提供交互的界面,并输出数据,而controller层则负责接收请求,并分发给相应的model来处理,然后调用view层来显示。
OOP面向对象编程
基本没人问
- 将现实世界的事物抽象成对象,关系抽象成类、继承,帮助人们实现对现实世界的抽象与数字建模
- 三大特性:封装、继承、多态
- 五大基本原则:
- 单一指责原则(类的功能单一)
- 开放封闭原则(对于拓展是开放的,对于修改是封闭的
- 里氏替换原则(子类可以代替父类出现
- 依赖倒置原则(高层次的模块不应该依赖与低层次的模块。具体实现应该依赖于抽象
- 接口分离原则(采用多个接口比一个通用接口好
设计模式
创建型、结构型、行为型
单例、工厂
适配器:将一个类的接口转换成另外一个接口
中介者:用一个中介对象来封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
网络安全
看公司产品,如果有涉及到还是很有必要准备一下的。我准备的比较少
XSS(跨站脚本攻击)
- 往Web页面里插入恶意Script代码,攻击用户
- 反射型XSS,
- 存储型XSS,往数据库里写代码
- HTTPONLY可以防止客户端从document读取cookie
- 使用
htmlspecialchars()函数
CSRF(跨站请求伪造)
- 用户C访问受信任网站A、登陆后产生了cookie,用户未退出A网站之前,打开了网站B,网站B返回了攻击性代码,并在用户不知情的情况下利用cookie间接访问了A网站
- 解决方案:验证码、检测Refer、利用Token
DDoS
- 攻击者借助代理服务器生成指向目标系统的合法请求,造成服务器资源耗尽
- 微信过年发红包就是一次人肉DDoS攻击
LINUX
基本没人问,用到查
常用命令
- netstat
- w :显示正在登录的用户
- cat /proc/meminfo 显示内存信息
- df -h 查看当前目录
- df -h /usr/ 查看指定目录磁盘使用情况
- du -sh /usr/ 计算文件夹大小
Top命令查看服务器状态的几个指标
- load average:1、5、15分钟内的服务器平均负载。
- 数值以CPU核数为准。多核处理器中,你的Load Average不应该高于处理器核心的总数量的70%。
- 各家的公式不尽相同,但都是用于衡量正在使用CPU的进程数量和正在等待CPU的进程数量,一句话就是runnable processes的数量。
- CPU usage: user,sys的百分比
- PhysMem:物理内存信息
反向面试
- 进去以后我主要负责什么?
- 能介绍一下团队情况吗?
- 团队氛围如何?
- 开发主要流程是怎样的?
- 常用的技术栈?
小鹅通
冒泡排序变形、某一遍排序下,两两之间比较,没有调换过位置,我是否能理解为整体有序?
快排思想、左右指针、一边排序结果是怎样的
公司项目的问题、没有提出问题
数据库innodb和myams的差距、(数据结构上)
索引优化方案、只回答,他没深入考察
如何理解框架中的自动加载
命名空间解决了什么问题
有没有写过框架
进程线程协程的区别
session和cookie的区别
cookie中的用户token请求 负载打到不同的机子上,登陆态不同,你觉得是什么原因,如何解决
并发和并行的区别
二
- 上台阶问题
- 针对笔试题继续深入。SQL优化可以从(ES)服务解决
然后面试官对我说,好我知道你的情况了。当我收到offer就知道他们挺缺人的。因为我对自己的表现也不是很满意,这是第一次裸面。
深信服
进程与线程的区别
进程间通信的几种方式
进程生存周期的5个阶段(创建、销毁)
HTTP状态码504是什么
Session和Cookie的区别
SSO思路
PHP数组相加和数组合并的区别
PHP数组取前十个的操作
PHP一个数组中插入另一个数组
找出一个数组中的在另一个数组是否重复,O(2n)
常见数据库引擎,以及之间的特点、差别
常见的几种索引
什么字段适合建立索引,什么字段不适合
索引未匹配到的原因
二分查找复杂度
职业规划
二
- 没怎么问问题,对着项目随便聊了聊,这个就看个人发挥了,不要太紧张。主要是想看你是什么样的人。
三
- HR面,同上。
目前是池里一只鱼,等待打捞
反思总结
- 表达能力需要不断提升
- 面试的过程需要懂得察言观色
- 注意每一个细节都会成为被筛掉的可能
- 世纪难题——我为了什么而活?